


Author: philippe.robert@gmail.com
Status: Request for discussion
Dependencies: CUDA (libcuda, libcudart)[, OpenCL]
Overview
One step further would be the integration of generic compute tasks, not limited to GPU computing ("throughput computing"). For example to support software based rendering on both CPUs and GPUs or compute intensive HPC tasks in a supercomputing centre.
Requirements
- Optional usage of CUDA [OpenCL] in Equalizer
- Scalability of compute tasks on multi-GPU and cluster systems
- Efficient shared GPU memory management
- Optimised node-to-node communication
Design Aspects
Equalizer uses Compounds to describe the execution of the rendering operations. The rendering is performed by Channels which are referenced by the compounds -- a channel belongs to a Window which again manages the GL context. Windows in turn are managed by a Pipe object which provides the threading logic. Usually, only one window is used per pipe. Internally, each Window uses an SystemWindow object which abstracts window-system specific functionality; i.e., using WGL, glX, or AGL. Similarly, an SystemPipe object is used by each pipe to handle the backend specific device implementation.
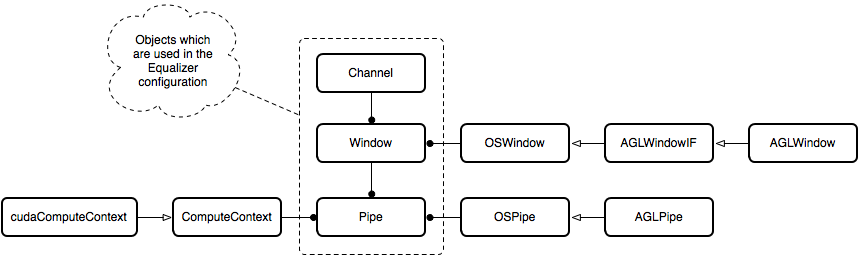
Figure 1: Overview class diagram (aside from AGL we currently also support glX and WGL)
When using CUDA one host thread can execute device code on exactly one GPU device; i.e., a host thread may have only one CUDA device context current at a time. To support multiple devices multiple host threads are thus required. This is a perfect match to the pipe abstraction of Equalizer. On the other hand, since GPU computing does not perform any rendering and as such does not rely on a drawable, the window abstraction does not fit (software based rendering is the exception here, since this requires some soft of framebuffer abstraction). Instead we use the pipe itself to execute the COMPUTE tasks defined in the compound description. This fits naturally to the design approach of both CUDA and OpenCL, and moreover we can avoid introducing another object hierarchy in parallel to the current pipe - window - channel model. As a consequence, we can simply use specific attributes on the pipe to set up the ComputeContext that provides the interface to either CUDA or OpenCL; see Figure 1.
In this context it would make sense to change the notion of a pipe into a more generic device abstraction which can represent a GPU, a CPU, or any other accelerator. Furthermore, a natural extension would then be to allow an arbitrary number of threads per device - imagine a multi-core CPU w/ hyperthreading, for example.
Internal Changes
In the first phase we target C for CUDA, later we will add support for OpenCL. The proposed changes are related to
- the proper initialisation of each participating pipe for GPU computing purposes,
- the synchronisation of shared (GPU) memory,
- the execution of CUDA kernels.
- Compute tasks are executed on a pipe which also performs OpenGL draw operations; i.e. interoperability with OpenGL is enabled.
- Compute tasks are executed on a compute-only device, such as a Tesla GPU or a designated GPU.
Initialisation
CUDA initialisation is handled by a cudaComputeContext object. In the future, other contexts might be used, such as clComputeContext for OpenCL. The context uses the specified cuda_device to select the appropriate compute device, or 0 if none is specified explicitely. Internally, the CUDA device is then selected by calling cudaSetDevice(). If OpenGL interoperability is required the specified CUDA device has to be set up accordingly. This mode can be selected using the attribute cuda_gl_interop which results in a call to cudaGLSetGLDevice() using the appropriate device identifier. Thus, the compute context is set up after the window (OpenGL context) initialisation.
To select the behaviour of synchronous CUDA function calls, either choose yield, block or spin for the attribute cuda_sync_mode. Internally this results in a call to cudaSetDeviceFlags() prior to any other runtime calls.
Execution Model
The execution model is based on a special-purpose COMPUTE task, analogous to the common rendering tasks. To integrate the compute tasks into the Equalizer execution model, pipes are referenced from the compound structure just as channels are used for rendering.
In the common case the COMPUTE tasks are part of the Equalizer rendering loop. To decouple the task execution from the rendering we might introduce special-purpose task queues on each compute device (pipe) to schedule asynchronous tasks (following the OpenCL design approach). In this model, synchronisation between tasks can be achieved using fence events, for example.
Equalizer provides the information required to launch a CUDA kernel as it is done with other, rendering specific parameters, such as the viewport for example. In the context of CUDA based GPU computing this is the range of the input domain to be processed by the particular GPU. It is left to the developer to manage data distribution and kernel-specific launch parameters:
- The correct offsets based on the compute range
- The number of blocks (grid dimension)
- The block parameters (block size)
- The shared memory size
Note that when the glinterop hint is specified, compute tasks can be scheduled before and/or after the common rendering tasks.
Shared Memory
Data can either be replicated or partitioned on the participating nodes. In case of (full or partial) data replication Equalizer provides a solution to synchronise memory changes between participating nodes; i.e., to quickly transfer memory changes from the (GPU-) memory of one node to the (GPU-) memory of another node.
In case of partitioned global data message passing functionality is needed to enable the communication between different nodes. This can be achieved using a more generalised event system. This is not part of this extension, though.
If data is replicated on multiple nodes, a subset of the data might subsequently have to be synchronised at runtime. To guarantee an optimal memory transfer performance a direct node-to-node communication model is established through shared memory proxy objects which handle the mapping and synchronisation of a specific memory range (see Figure 2). The memory transfer from/to the GPU is performed implicitly by the proxy objects as part of the map/sync/dirty/commit cycle.
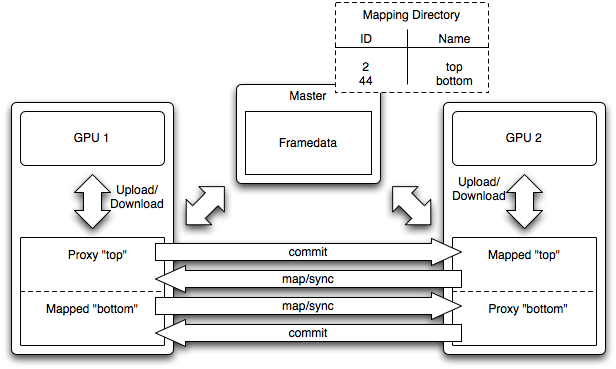
Figure 2: Data replication using proxy objects.
To simplify the initialisation of the proxy objects a global naming directory is used which links custom proxy names to system defined shared memory IDs. This directory is part of the shared data and thus can be used by all nodes with only little overhead. In case where the same memory range is modified by more than one node it is up to the application to handle the synchronisation. Please note that even though it is possible to map multiple proxies to the same memory range it is not actually recommended.
The memory update process could be further optimised using a RMA based network implementation.
API
Data Distribution
class ComputeContext
{
};
File Format
Extension
Example
In this example 2 compute units are used, one on a compute-only device, the other interoperating with the rendering:
pipe
{
name "gpu1"
window
{
name "window"
channel
{
name "channel1"
}
}
attributes
{
cuda_gl_interop on
cuda_sync_mode block
cuda_device 0
}
}
pipe
{
name "gpu2"
attributes
{
cuda_sync_mode block
cuda_device 1
}
}
compound
{
channel "channel1"
compound
{
name "mixed-mode compound"
}
compound
{
name "compute compound"
}
}
Open Issues
- CUDA Implementation:
Do we use the CUDA driver API or the CUDA runtime API for the
implementation? These APIs are mutually exclusive.
For now we use the CUDA runtime API. It eases device code management by providing implicit initialization, context and module management. The host code generated by nvcc is based on the CUDA runtime API, so applications that link to this code must use the CUDA runtime API. Finally, device emulation only works for code written for the runtime API.
- Equalizer Integration:
Do we have to introduce new abstractions as equivalent to Windows and
Channels?
No. GPU compute tasks can be implemented on pipes (devices).
- Generic Compositing:
Can we provide a generic compositing solution for arbitrary chunks of
memory (think of software based rendering)?
- Compound Definition:
How are generic devices/pipes integrated into the compound description?
- Dynamic Workload Balancing:
Do we provide separate timing values to balance the compute tasks, or
should they be integrated into the normal loadbalancing?
- Kernel Launch Parameters:
Should the grid and block parameters be transported by Equalizer, or
should this be done by the programmer using regular frame data? What if
multiple kernels are used in one compute task, do they use the same
launch configuration?
- Memory Proxies:
Should we provide special-purpose implementations of shared memory
proxy objects or just one abstract base class? E.g., a global array?
- Asynchronous Memory Transfer:
How can we use asynchronous communication to hide the latency of the
host-device transfer?