


Author: Stefan Eilemann
State:
- Implemented in 0.9.1
- Sliding ack window and early acks in 1.0-alpha
Overview
This document explores the usage of multicast or broadcast to speed up
one-to-many communication in Equalizer, i.e., the data distribution
for co::Object.
Requirements
- Optional usage of a many-to-one network protocols
- Reliable and in-order data transmission
- Usage of point-to-point and many-to-one communication for one data transfer, e.g., to update clients within the subnet and outside.
- High performance, target should be 80% speed when distributing to 10 clients compared to one point-to-point transfer.
- Usage of many-to-one communication for:
co::Objectmappingco::Object::commit
Multicast Primer
A multicast group is defined by the IPv4 multicast address. A multicast sender binds and connects a socket to the multicast address in order to send data to all multicast receivers. A multicast receiver listens on the multicast address, accepts a new sender which will return a handle (file descriptor) to receive data from the sender.
Design
Pragmatic General Multicast (PGM)
PGM seems like a promising protocol, but has the disadvantage of not providing the reliability needed for Equalizer. PGM uses a send window to buffer data, and a client my only request retransmissions within this send window. Whenever a client reads data too slowly, the local implementation disconnects this client from the PGM sender. We can not recover from this disconnect, since it implies that data was lost.
Reliable Stream Protocol (RSP)
Collage implements a reliable stream protocol (RSP) using UDP multicast as a low-level transport. Equalizer 0.9.1 allows to use both PGM and RSP as a multicast protocol. We strongly recommend using RSP and will possibly retire PGM support in the future. RSP provides the following features:
- Full reliablity using active acks, a slow receiver will eventually slow down the sender
- High-performance implementation:
- Read and write buffering with lock-free queueing
- Merging of small writes
- Early nacks (negative acknowledgements)
- Early acks, sliding sender-side ack window (1.0-alpha)
- Nack merging
- Multicast send interface selection
- Event-based (Windows) or FD-based (Posix) notification mechanism
It does not yet implement (TODO-list):
- Client connects and disconnects during active write operations
- Automatic MTU discovery between Windows and non-Windows hosts
- Infiniband support
- TTL selection, i.e., multicast traffic will not leave the local subnet
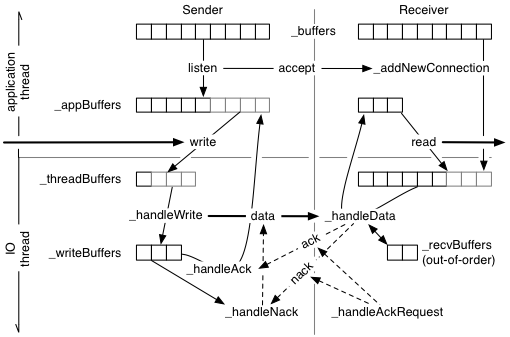
Each member of the multicast groups call listen on its RSP
connection
(API
documentation). This creates an I/O thread for this multicast
connection. The connection discovers all other members in the multicast group
during the initialization and creates one connected RSPConnection
for each group member. A new member is signaled on the listening connection,
and can be retrieved using accept. On each process there is therefore one
listening and n connected connections for each multicast group. Data send is
also received locally, that is, there is one connected RSPConnection for the
local sender.
Each RSP connection has a number of data buffers (64 Windows/1024 others) of
mtu size (65000 Windows/1470 others). These buffers are circulated between the
the application and IO thread during operations, ultimately causing the
application thread to block in read or write if no
buffers are available. Care has been taken in the implementation to use
lock-free queues and batching locked operations where possible. This ensures a
high parallelism between the application and network communications.
The RSP communication protocol follows roughly the following pseudo-code algorithm:
[Application thread]
RSPConnection::write( buffer, size )
numPackets = size / _mtu;
for each packet
if no free packet available
wake up I/O thread to trigger processing
get free packet from _appBuffers [may block]
copy data to packet
enqueue packet to _threadBuffers
wake up I/O thread to trigger processing
[RSPConnection IO thread]
RSPConnection::handleTimeout
processOutgoing()
RSPConnection::handleData
handleData()
processOutgoing()
RSPConnection::processOutgoing
if repeat requests pending
send one repeat
speed up by bandwidth * RSP_ERROR_UPSCALE permille
set timeout to 0
else if write pending (_threadBuffers not empty)
merge pending write buffers up to mtu size
update packet sequence
send one data packet
save packet for repetion (_writeBuffers)
speed up by bandwidth * RSP_ERROR_UPSCALE permille
if _writeBuffers not empty and _threadBuffers empty
(i.e. still need ack and nothing to write)
if timeout exceeded
send ack request
set timeout
RSPConnection::handleData
if data packet in order
try to get free packet from application thread (_threadBuffers)
if no packet available
drop data packet
else
enqueue data packet to application (_appBuffers)
enqueue in-order saved early packets (_recvBuffers)
update sequence
if sequence % ack frequency
send ack to sender
else if earlier packet already received (repetition for other receiver)
drop packet
else if early future packet
try to get free packet from application thread (_threadBuffers)
if no packet available
drop data packet
else
save packet (_recvBuffers)
send NAck for all packets not received before this one
RSPConnection::handleAck
update receiver's sequence
if all other receiver's have later sequence
enqueue packets up to sequence for own read operation
_writeBuffers -> _appBuffers
RSPConnection::handleNAck
queue repeat requests
slow down lost * sendRate * RSP_ERROR_DOWNSCALE permille
(up to bandwidth >> RSP_MIN_SENDRATE_SHIFT)
RSPConnection::handleAckRequest
if own sequence smaller than request
send nack with all missing packets
else
send ack with own sequence
[Application thread]
RSPConnection::read( buffer, size )
while data to be read
if no current read buffer
get read buffer from _appBuffers [may block]
copy data from read buffer to application memory
if read buffer fully used
push buffer to IO thread (_threadBuffers)
else
update read buffer size
Object Mapping
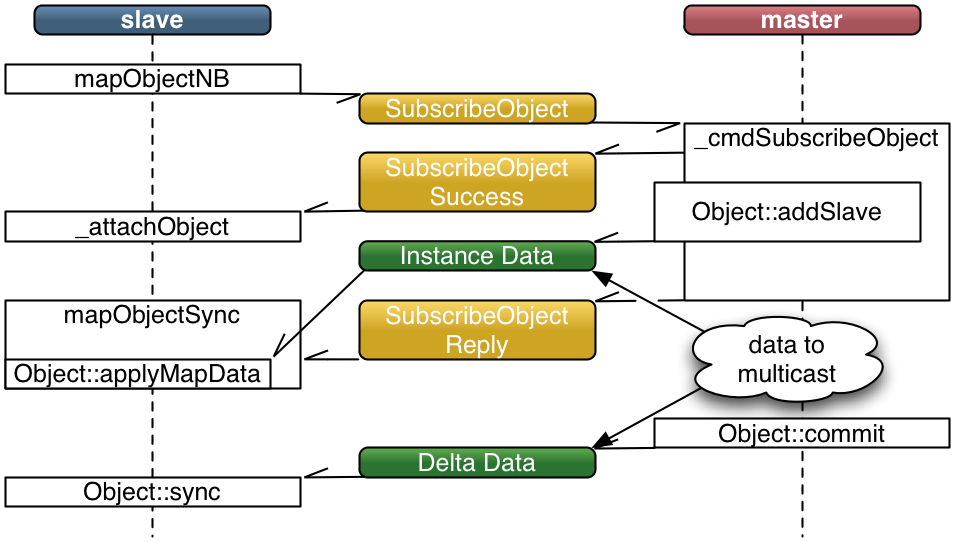
Object mapping is requested by the slave instance. The master instance does not know beforehand the list of slaves, and can therefore not optimize the object mapping in the current implementation.
In order to overcome this limitation, there are two possibilities: A per-node object instance data cache or deferring the initialization be separating it from the object mapping.
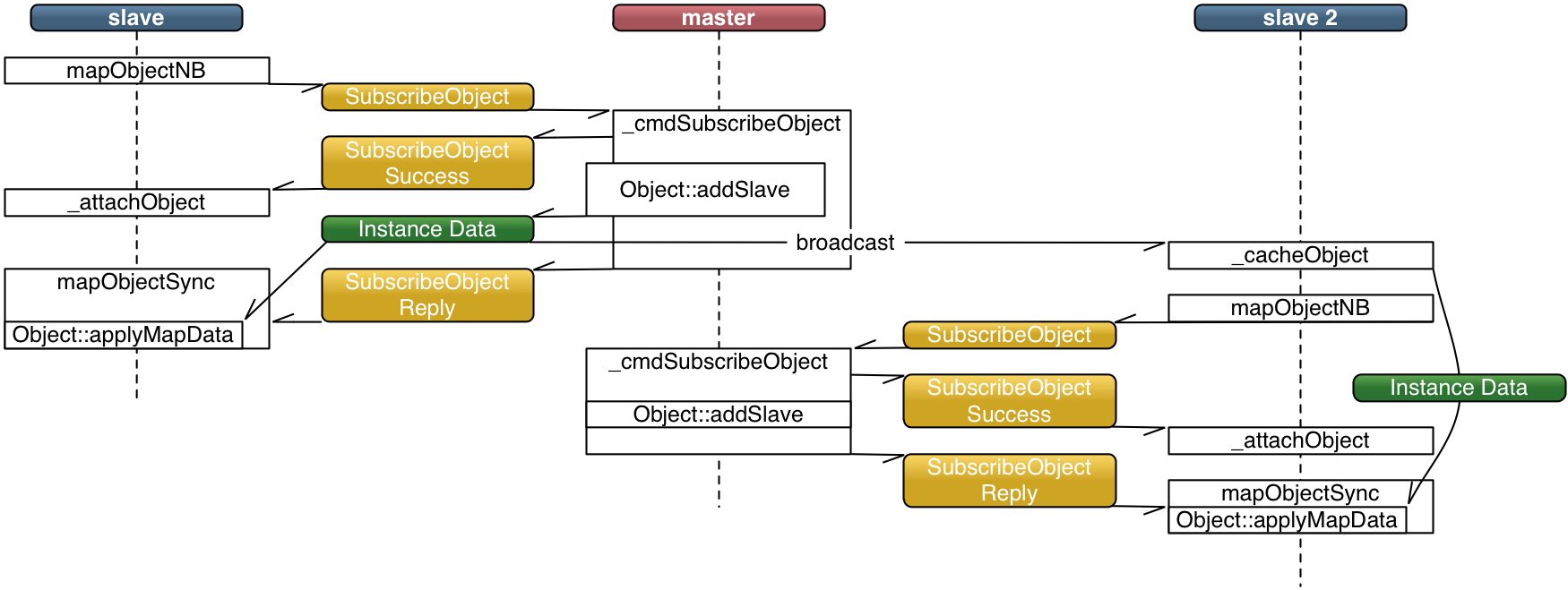
When using an object instance data cache, the master instance broadcasts the object instance data to the first slave node mapping the object. Each node receiving the data will enter it into its own cache. Subsequent slave nodes use the instance data from the cache and only need a registration handshake with the master instance.
When using a delayed initialization, no data is transmitted during mapping. The master instance registers the slave nodes. The first slave node will explicitely request the initialization data at a later time (before the first sync?), upon which the master will broadcast the information to all known slaves.
Instance Cache
Caching instance data has a performance penalty for the cache management and multicast data transfer. Multicast transfer has to be carefully selected to not overload the network if multiple Equalizer session run within the same subnet. The caching algorithm needs to yield high hit rates to avoid re-broadcasting instance data and conservative memory usage (instance data is typically only needed during initialization of a new model).
To optimize instance data broadcast, slave instance have to explicitely declare interest in a certain type of data. A set of objects belongs to the same type of data, typically all scene graph nodes of one model have the same type, but scene graph nodes of different models have different types. Each render client subscribes to instance data broadcasts of the model it is currently mapping, and unsubscribes after all model data has been mapped.
ObjectCache& Session::getObjectCache();
uint32_t Object::getType() const;
class ObjectCache
{
public:
void request( const uint32_t type );
void ignore( const uint32_t type );
private:
stde::hash_map< uint32_t, NodeVector > _registrations;
};
Delayed Initialization
The delayed initialization decouples the registration from the initialization during mapping. This allows the master to send the initialization data to all registered slave instances on the first initialization request.
The main issue with delayed initialization is that it does not have a lot of potential for the typical hierarchical data structures used in scene graphs. In order to register children of a given node, the node has to be initialized, which causes the registration and mapping to happen almost at the same time.
Object Commit
During commit time, all receivers are know. The master needs to build a connection list containing the multi-point connection(s) to the 'local' clients and the point-to-point connections to the 'remote' clients.
API
File Format
node
{
connection { type TCPIP }
connection
{
type MCIP | RSP | PGM
hostname "239.255.42.42"
interface "10.1.1.1"
port 4242
}
}
Implementation
Benchmark PGM on Windows
PGM listening connection
o readFD is a listening socket FD
o writeFD is a connected socket FD to group
PGM connected connection
o readFD is result from accept
o writeFD is shared with listening connection
Node::connect( peer, TCPConnection )
search peer for PGM connection description for our PGM connection(s)
-> send NodeID to PGM connection, creates connected connection on peer
Node::_handleConnect
accept new connection
if new connection is PGM connection
read peer node id from new connection
find existing, connected node
set new PGM connection on node
*MasterCM::_cmdCommit
DataOStream::enable( slaves )
prefer and filter duplicate PGM connections
[Opt: Cache result in MasterCM?]
Session::mapObject
mapObjectNB
lookup and pin object instance data in cache
send SubscribeObject packet with known instance version
mapObjectSync
wait on SubscribeObjectReply
retrieve and unpin pinned object instance data from cache
Object::applyMapData( instance data )
Session::_cmdSubsribeObject
send SubscribeObjectSuccess
Object::addSlave( nodeID, cachedVersionStart, cachedVersionEnd )
send missing versions
...
return first version to apply
Session::_cmdInstance
if nodeID is ours
forward to object instance
potentially add to cache
Restrictions
References
- Windows XP PGM Implementation (Install Control Panel -> Add or Remove Programs -> Add or Remove Windows Components -> Message Queueing)
- OpenPGM Implementation
Issues
1. How are late joins to the multicast group handled, e.g., caused by a layout switch?
Resolved: The Equalizer implementation has to ensure that no application code is executed during node initialization and exit.
A layout switch currently ensures this partly. The eq::Config finishes all frames on a layout switch in startFrame. The application and all render clients have to be blocked until eq::server::Config::_updateRunning is finished.
2. How are the 'cache enable' requests synced during rendering, e.g., when running in DPlex?
Open
Option 1: The application has to call finishAllFrames, which will cause the render clients to restart almost simultaneously.
Option 2: The application can synchronize all or a subset of the clients
without blocking the rest or the application.
The issues is what to sync: Most of the data-to-be-mapped is view-specific,
e.g., the model, and might be shared among multiple views.
3. Which network adapter is used in multi-network hosts?
Resolved: The 'interface' connection parameter is used to set the IP address or hostname of the outgoing multicast interface.
By default, the first interface is used on Windows XP (MSDN doc), but the RM_SET_SEND_IF socket option can be used to define another interface by IP address (MSDN doc), probably using the interface's unicast address (to be verified).